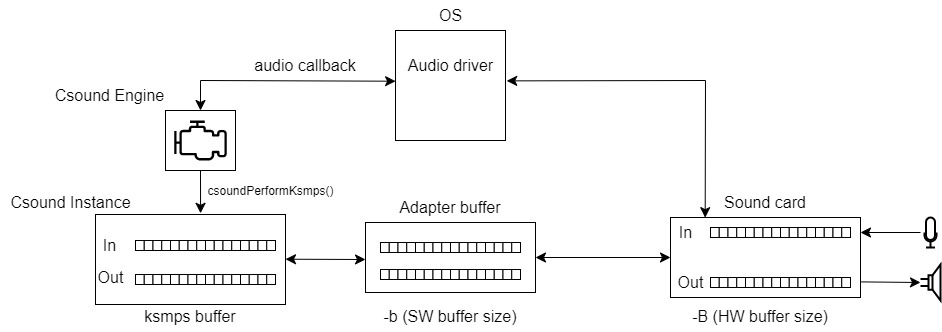
I have problem understanding relationships between ksmps buffer, SW buffer and HW buffer.
To be more specific let’s consider following cases:
Case 1) ksmps buffer < SW buffer → will csound engine call csoundPerformKsmps() several times immediately one after another until SW buffer is full?
Case 2) SW buffer < HW buffer → will csound engine again, like in case 1, call csoundPerformKsmps() several times until enough SW buffers are filled in order to fill one HW buffer?
Case 3) non-integer size ratio between three mentioned buffers → I’ve experimented a bit with different buffer sizes and non-integer ratios and I didn’t notice that something didn’t work. Does this mean that SW buffer size is somehow automatically set to a value that makes sure that everything works well?
I’ve tried to visualize “complete” system in the attached image to make it easier to understand what I mean.
(i can not help you with any of your questions, but i am a maintainer of the Csound manual.
If all is demystified, may i add your visualization image to the manual: Real-Time Audio ?)
Of course! I would be extremely honored! Here is also a pdf file if you want it.
If you like you can use the image right away or you can wait until I get some answers and understand it a bit better and then I can also update it accordingly, if needed.
To elaborate a bit more my question and what is behind it…
If I understand it correctly and the system can be described as I did on image above, then this would mean that the overall latency of our audio system is determined by the size of the longest buffer:
Furthermore, since the latency is determined by the longest of those three buffers, it makes sense to set other two buffers to the same length. That would not change anything regarding latency but it would make it easier for the OS and Csound engine to perform smoothly.
An exception to this could be, if an instrument really needs low ksmps because it correlates with the sound quality as mentioned here (Real-Time Audio). I don’t have any experience on that point so I will leave it as is.
On the other hand, one can also argue that lower ksmps gives better time resolution but let’s consider this case:
sr = 48000 samples/second
-B = 480 samples
-b = 480 samples
ksmps = 240
In this case audio callback function would be called approx. every 10ms and in that moment csound engine would need to call csoundPerformKsmps() two times in order to generate enough samples to serve that callback function. I assume that csoundPerformKsmps() would be called two times directly one after another which would then mean that our time resolution actually depends on how long our system needs to calculate one k-cycle. If our system needs i.e. 1ms to calculate one k-cycle this would mean that second csoundPerformKsmps() would happen 1ms after the callback function is generated and not 5ms as one could expect. This would result in 10ms-1ms=9ms time resolution and that is why, I think, it is misleading to say that ksmps dictates time resolution (responsiveness) of our system.
if you do not get any reply here, you might try Discord
or
Csound@listserv.heanet.ie (you can’t add thre image but you can link to this place so the image can be seen)